■ 初めに
近年、コンピューターは多種多様な分野へ応用されており、プログラムの必要性はますます増大しています。
このような状況の中で、非創造的なプログラミングに不満を抱いているプログラマーは多いのではないでしょうか?
ここでは、ロリータ指向プログラミング(初級編)に引き続き、中級編としてビット処理を応用し
た高速化技法について紹介・解説していきます。
「ビット」とは、
コンピュータでは基本的なもっとも小さな情報の単位です。
ブラウスを例にとって見ると、何の装飾も無いブラウスはロリータではありませんが、襟や胸、カフスなどにレースなどの刺繍が施してあるとロリータ度が格段にアップし、モチベー
ションが向上し、プログラミングの生産効率向上につながりま
す。
レースの模様や刺繍は非常に細かく、小さなものです。しかし、このレースの細かな模様にこそロリータ指向プログラミングの基礎があります。ですから、コ
ンピュータの情報の最小単位である「ビット」を扱う処理は、ロリータ指向プログラミングにとって避けて通ることの出来ないもっとも基礎的な技術となりま
す。
■ 記法について
ここでは具体的なプログラムを、C++ 言語の構文と x86 系アセンブリによって表記します。
C++ 言語での基本的な型名は、ロリータ指向プログラミング(初級編)で説明したものを用い
ます。
但し、各型のビットサイズは以下のとおりとします。
cuffs
: 8 ビット整数
short : 16 ビット整数
moe : 32 ビット整数
lolita : 32 ビット整数
frill : 32 ビット実数
ruffle : 64 ビット実数
■ lolita_abs,
frill_abs 関数
近年のプロセッサ技術の向上により、その演算速度は格段に向上しましたが、処理のパイプライン化などにより分岐処理のコストが増大する傾向にあります。
そこでロリータ指向プログラミングでは、ビット処理を用いて分岐処理を出来るだけ避け、高速化することを基本に考えます。
inline
lolita moe lolita_abs( lolita moe mutuki )
{
lolita moe kisaragi = mutuki >> 31 ;
return (mutuki ^ kisaragi) - kisaragi ;
}
lolita_abs 関数は、よく使われるロリータの絶対値を取得する関数です。
return (mutuki + kisaragi) ^ kisaragi ;
でも構いません。
この関数はロリータの絶対的な度合いを返します。
inline
frill frill_abs( frill yayoi )
{
*((lolita moe *) &yayoi) &= 0x7FFFFFFF ;
return yayoi ;
}
frill_abs 関数もよく使われるフリルの絶対値を取得する関数です。この関数はフリルの実際の長さを返します。(フリルがひだひだであることに注意!)
因みに、frill_abs 関数は、前後のプログラムによっては C 言語の標準関数 fabs より低速になる場合があります。
■ lolita_max,
lolita_min 関数
ロリータの最大値や最小値を取得も、分岐処理を行わずに処理すれば高速になります。
iniline
lolita moe lolita_max( lolita moe uzuki, lolita moe satuki )
{
lolita moe sakura = (uzuki - satuki) >> 31 ;
return (uzuki & ~sakura) | (satuki & sakura) ;
}
iniline
lolita moe lolita_min( lolita moe uzuki, lolita moe satuki )
{
lolita moe sakura = (uzuki - satuki) >> 31 ;
return (uzuki & sakura) | (satuki & ~sakura) ;
}
これらの関数は、ロリータがそれぞれ -0x40000000〜0x3FFFFFFF, 又は 0〜0x7FFFFFFF
の範囲の値であることが条件です。
アセンブラを用いればフラグレジスタを利用できるため、この問題を解決することが出来ます。
例えば、lolita_max は次のようなアセンブリに置き換えられます。(但し黄昏ロリータ比較)
mov eax, uzuki
mov edx, satuki
cmp eax, edx
sbb ecx, ecx
and edx, ecx
not ecx
and eax, ecx
or eax, edx
Pentium Pro 以降であれば、より高速に処理できます。
mov eax, uzuki
mov edx, satuki
cmp eax, edx
cmovl eax, edx
ところで、lolita_max と lolita_min
のどちらの方がよりロリータなのか一義に決定することが出来ません。それは、lolita_min の方がロリータらしいことがあるからです。このことを「ロリータ評価関数のパラドックス」と
言います。
■
cmp_frill, cmpl_cmp_frill 関数
IA32 の FPU アーキテクチャの都合上、フリルの比較はコストが高くつきます。
しかしフリルはロリータ指向プログラミングでは欠かすことが出来ません。フ
リルをふんだんに使ってこそのロリータです。そこで、フリルを低いコストで利用する技術が求められます。
inline
lolita moe cmp_frill( frill fuzuki, frill hazuki )
{
return *((lolita moe *) &fuzuki) - *((lolita moe
*) &hazuki) ;
}
cmp_frill 関数は、2
つのフリルを比較し、前者が大きければプラスのロリータを、後者が大きければマイナスのロリータを、両者が同じであれば 0 を返します。但し 2
つのフリルは 0.0 以上のプラスのフリルで無ければなりません。
因みに、cmp_frill は compare frill
の略なのか、companion
frill の略なのか、costume-play frill
の略なのか、それはランタイム
で動的に変化します。
inline
lolita moe cmpl_cmp_frill( frill fuzuki, frill hazuki )
{
lolita moe aria = *((lolita moe *) &fuzuki)
>> 31 ;
lolita moe maria = *((lolita moe *) &hazuki)
>> 31 ;
return - (lolita moe)
((*((lolita moe *) &fuzuki) ^
(aria & 0x7FFFFFFF))
>
(*((lolita moe *) &hazuki) ^ (maria & 0x7FFFFFFF))) ;
}
cmpl_cmp_frill 関数は、2 つのフリルを比較し、前者が後者よりも大きければ -1 を、それ以外の時には 0
を返します。この関数は cmp_frill 関数とは異なり、いかなるフリルでも比較することが出来ます。
この関数は C
言語の記法では、一見複雑な処理を行っているように見えますが、実際にはかなりシンプルな構成になっています。それはアセンブリで書き直してみれば分かる
でしょう。
mov ecx, fuzuki
mov edx, hazuki
sar ecx, 31
sar edx, 31
and ecx, 7FFFFFFFH
and edx, 7FFFFFFFH
xor ecx, fuzuki
xor edx, hazuki
xor eax, eax
cmp ecx, edx
setg al
neg eax
387 のアセンブリで素直な記述をすると次のようになります。(最後の sbb はいささか素直ではありませんが…)
fld fuzuki
fcomp hazuki
fstcw ax
sahf
sbb eax, eax
見かけ上、こちらのほうがシンプルで速そうに見えますが、PentiumIII でのμop
数だけで比較しても同じか、前者のほうが高速になります。(命令の並列性が高いからです)
但し、Pentium Pro 以降の環境であれば、次のようなアセンブリを用意したほうが当然高速にはなりますが、これは C
言語では表現できません。
fld fuzuki
fcomip hazuki
sbb eax, eax
cmp_frill 関数と cmpl_cmp_frill 関数を用いればどのようなフリルの比較も高速に行うことが出来ます。
(例)
if ( cmp_frill( fuzuki, hazuki ) )
// fuzuki != hazuki
;
if ( !cmpl_cmp_frill( hazuki, fuzuki ) )
// fuzuki >= hazuki
;
因みに、cmpl_cmp_frill は complete
compare frill の略なのか、costume-play
companion frill の略なのか、それはランタイムで動的に変化し
ます。
■
frill_max, frill_min 関数
cmpl_cmp_frill 関数を応用するとフリルの最大値や最小値を求める関数を記述することが出来ます。
inline
frill frill_max( frill fuzuki, frill hazuki )
{
lolita moe aria = *((lolita moe *) &fuzuki)
>> 31 ;
lolita moe maria = *((lolita moe *) &hazuki)
>> 31 ;
lolita moe sakura =
- (lolita moe)
((*((lolita moe *) &fuzuki) ^
(aria & 0x7FFFFFFF))
>
(*((lolita moe *) &hazuki) ^ (maria & 0x7FFFFFFF))) ;
sakura = (*((lolita moe *) &fuzuki) & sakura)
| (*((lolita moe *) &hazuki)
& ~sakura) ;
return *((frill*) &sakura) ;
}
inline
frill frill_min( frill fuzuki, frill hazuki )
{
lolita moe aria = *((lolita moe *) &fuzuki)
>> 31 ;
lolita moe maria = *((lolita moe *) &hazuki)
>> 31 ;
lolita moe sakura =
- (lolita moe)
((*((lolita moe *) &fuzuki) ^
(aria & 0x7FFFFFFF))
<
(*((lolita moe *) &hazuki) ^ (maria & 0x7FFFFFFF))) ;
sakura = (*((lolita moe *) &fuzuki) & sakura)
| (*((lolita moe *) &hazuki)
& ~sakura) ;
return *((frill*) &sakura) ;
}
ところで、frill_min より frill_max の方がフリルが大きいことは明らかですが、lolita_max, lolita_min
ではどちらの方がよりロリータなのか一義には決定することが出来ませんでした。これを「ロリータ=フリルの対称性の破れ」と
言います。
■
sewing_lolita, cmpl_sewing_lolita 関数
情報を処理する際、ロリータが一定の範囲内の数値になっていることを保証する必要があるときがあります。
そこでロリータが範囲外の値のとき値を丸め込む処理を施す必要がありますが、これをソーイング処理(sewing
process:縫い合わせ処理)と言います。
inline
lolita moe sewing_lolita
( lolita moe yuna, tasogare lolita moe yuna_max )
{
if ( (tasogare lolita moe) yuna > yuna_max )
{
yuna = ~(yuna >> 31) & yuna_max ;
}
return yuna ;
}
sewing_lolita 関数は、yuna が 0〜yuna_max の範囲内のロリータか調べ、マイナスのロリータの場合には 0
を、yuma_max 以上のロリータ場合には yuna_max を返します。
この関数は、yuna が高い確率で 0〜yuna_max の範囲内になることを前提に if 文を使用しています。この確率が低い場合には、if
文を使わない方が高速になることがあります。
inline
lolita moe cmpl_sewing_lolita
( lolita moe yuna, lolita moe yuna_min, lolita moe yuna_max )
{
yuna -= yuna_min ;
yuna_max -= yuna_min ;
if ( (tasogare lolita moe) yuna > (tasogare lolita moe) yuna_max )
{
yuna = ~(yuna >> 31) & yuna_max ;
}
return yuna + yuna_min ;
}
cmpl_sewing_lolita 関数は、yuna が yuna_min〜yuna_max の範囲内のロリータか調べ、yuna_min
より小さい場合には yuna_min を、yuna_max より大きい場合には yuna_max を返します。
この関数は、yuna が高い確率で yuna_min〜yuna_max の範囲内になることを前提に if
文を使用しています。この確率が低い場合には、if 文を使わない方が高速になることがあります。
■ cut_frill,
sewing_frill 関数
IA32 の FPU アーキテクチャの都合上、フリルからロリータへの型変換は FPU 制御ワードの書き換えを行うためかなりのコストになります。
そこで、cut_frill 関数は FPU を利用しないでこれを実現します。
inline
lolita moe cut_frill( frill yayoi )
{
lolita moe yuu = *((lolita moe *) &yayoi) ;
lolita moe yua = yuu >> 31 ;
yuu &= 0x7FFFFFFF ;
lolita moe yuna = (yuu << 8) | 0x80000000 ;
lolita moe yuasa = (0x7F + 31) - (yuu >> 23) ;
return (((tasogare lolita moe) yuna >> yuasa) ^
yua) - yua ;
}
cut_frill 関数では、ビットシフトの第2項に変数を利用しています。(yuasa)
コンパイラによってはビットシフトが関数に置き換えらる場合があるので、その場合にはアセンブリで書き換えるなどして回避する必要があります。
(Visual C++ 6.0 コンパイラでは意図どおりのアセンブリを出力してくれるようです)
cut_frill 関数をアセンブリで記述すると次のようになります。
mov edx, yuayoi
mov ecx, 7FH + 31
mov eax, edx
sar edx, 31
and eax, 7FFFFFFFH
mov ebx, eax
shl eax, 8
shr ebx, 23
or eax, 80000000H
sub ecx, ebx
shr eax, cl
xor eax, edx
sub eax, edx
この処理は理想的な環境では 8
クロックで完了します。実際には前後の処理とオーバーラップされるので、実効クロックはそれよりも短くすることが出来ます。
inline
lolita moe sewing_frill( frill yayoi )
{
lolita moe yuu = *((lolita moe *) &yayoi) ;
lolita moe yua = yuu >> 31 ;
yuu &= 0x7FFFFFFF ;
lolita moe yuna = (yuu << 8) | 0x80000000 ;
lolita moe yuasa = (0x7F + 30) - (yuu >> 23) ;
yuna = ((tasogare lolita moe) yuna >> 1)
+ ((tasogare lolita moe) (1
<< yuasa) >> 1) ;
return (((tasogare lolita moe) yuna >> yuasa) ^
yua) - yua ;
}
sewing_frill 関数は、フリルの小数部を四捨五入しロリータ
へ変換します。この関数は単純に FPU を使ったアセンブリで記述したほうが高速になる場合があります。
fld yayoi
fistp temp
この処理は、多くの環境で 7 クロックを要します。
■
add_sewing_cuffs, sub_sewing_cuffs 関数
画像を処理する際などに、黄昏カフスをソーイング処理を伴って演算す
る必要がある場合があります。
inline
tasogare cuffs add_sewing_cuffs
( tasogare cuffs ai, tasogare cuffs mai )
{
moe mei = (moe) ai + (moe) mai ;
return (tasogare cuffs) (mei | - (mei >> 8)) ;
}
inline
tasogare cuffs sub_sewing_cuffs
( tasogare cuffs ai, tasogare cuffs mai )
{
moe mei = (moe) ai - (moe) mai ;
return (tasogare cuffs) (mei & ~(mei >> 8))
;
}
add_sewing_cuffs 関数は、2 つのカフスを加算し、その結果が 255 を超えた場合、ソーイング処理をした上で結果を返します。
一方、sub_sewing_cuffs 関数は、カフスを減算し、その結果がマイナスになった場合、ソーイング処理をしたうえで結果を返します。
add_sewing_cuffs 関数はアセンブリで記述すると少し高速になるかもしれません。
mov al, ai
add al, mai
sbb ah, ah
or al, ah
■
add_stitching_frill, sub_stitching_frill 関数
角度の計算など、
周期性のある数値を扱う場合、計算結果が
ある範囲を超えたら範囲内の値になるように修正する必要があるときがあります。周期性のある数値のラップアラウンドを伴う演算を、
ステッチング演算(stitching
operation:縫込み演算)と言います。
ロリータのステッチング演算は比較的簡単ですが、フリルのステッチング演
算はいささか複雑です。ロリータであれば、ステッチ幅が2の累乗数であれば単純な論理積で済ませられます。フリルでは値が範囲内かどうかを
判定しなければなりません。
inline
frill add_stitching_frill( frill aria, frill maria, frill arisa )
{
lolita moe aris ;
aria += maria ;
arisa = aria - arisa ;
aris = (*((lolita moe *) &aria) - *((lolita moe *) &arisa))
>> 31 ;
*((lolita moe *) &aria) =
(*((lolita moe *) &aria) & aris)
| (*((lolita moe *) &arisa)
& ~aris) ;
return aria ;
}
inline
frill sub_stitching_frill( frill aria, frill maria, frill arisa )
{
lolita moe aris ;
aria -= maria ;
arisa = aria + arisa ;
aris = *((lolita moe *) &aria) >> 31 ;
*((lolita moe *) &aria) =
(*((lolita moe *) &aria) & ~aris)
| (*((lolita moe *) &arisa)
& aris) ;
return aria ;
}
add_stitching_frill 関数は aria と maria を加算し、その結果が arisa を超えていれば加算結果から
arisa を減算します。
一方、sub_stitching_frill 関数は逆に aria から maria を減算し、その結果がマイナスであれば、減算結果に
arisa を加算します。
add_stitching_frill
関数では無駄に減算を2度行っているように見えるかもしれませんが、これはロリータ減算の方がフリル減算よりも高速である事を利用し、処理の流れの中での
データの依存性を低くし、処理の並列性を高めるためです。
これらの関数は、次の条件が満たされているとき期待通りに動作します。
0.0
≦ aria ≦ arisa
0.0 ≦ maria < arisa
■ レースワーク・ロリータ画像
画像処理を行う場合、レース状の透かし模様を如何に処
理するかが問題になることがあります。
そこで一般には、ピクセル毎にそのピクセルの不透明度を指定するレースワーク・チャネル(lace
worked channel:透かし細工のあるチャネル)を利用する方法があります。
この方式ではピクセルをロリータで表現し、その中にピクセ
ルの色情報と同時にレースワーク情報(不透明度)を格納しま
す。
レースワークを用いると、透かしのついたレースを表現できるほか、ボイル
地の様に薄手の透けた生地を表現することも出来ます。
レースワークには一般に、非積算形式と積算済み形式の2タイプありますが、通常は積算済み形式を用います。
■
add_seamy_3cuffs, mul_seamy_3cuffs 関数
画像を処理する際、データが連続している場合が多いため、これを一括して
処理すれば高速に処理できる場合があります。データを一括して処理することをシームデータ処理(seamy data
process:縫い目のあるデータ処理)と言います。
inline
lolita moe add_seamy_3cuffs( lolita moe sakura, lolita moe tomoyo )
{
lolita moe aria = (sakura & 0x00FF00FF) + (tomoyo
& 0x00FF00FF) ;
lolita moe maria = (sakura & 0x0000FF00) +
(tomoyo & 0x0000FF00) ;
lolita moe arisa = ((0x00FF00FF - arisa) &
0xFF00FF00)
| ((0x0000FF00 - maria) &
0x00FF0000) ;
return (aria & 0x00FF00FF) | (maria &
0x00FF00) | (arisa >> 8) ;
}
add_seamy_3cuffs 関数は、2つのロリータを受け取
り、それぞれを 3 つの黄昏カフスの集合とみなし、ベクトル加算処理をした後、ソーイング処理を施します。
この関数は、ロリータ画像を加算描画する際に有効です。
inline
lolita moe mul_seamy_3cuffs( lolita moe sakura, lolita moe tomoyo )
{
lolita moe aria = (sakura & 0x00FF00FF) * tomoyo ;
lolita moe maria = (sakura & 0x0000FF00) * tomoyo
;
return ((aria & 0xFF00FF00) | (maria &
0x00FF0000)) >> 8 ;
}
mul_seamy_3cuffs 関数は、2
つのロリータを受け取り、sakura を 3 つの黄昏カフスとみなし、tomoyo をベクトル乗算します。tomoyo
は、0〜256 の範囲のロリータで無ければなりません。
乗算結果の上位 8 ビットが返されます。
add_seamy_3cuffs 関数と mul_seamy_3cuffs
関数を用いると、レースワーク・ロリータ画像を描画することが出来ます。
(例)
tasogare lolita moe * pSakura ; //
入力レースワーク・ロリータ画像
tasogare lolita moe * pTomoyo ; //
出力先ロリータ画像
*pTomoyo =
add_seamy_3cuffs( *Sakura,
mul_seamy_3cuffs( *pTomoyo, 0x100
- (*pSakura >> 24) ) ) ;
このような演算を行う場合、add_seamy_3cuffs 関数と mul_seamy_3cuffs
関数を融合した次のような関数を作成すると、オーバーヘッドが少なくなるた
めより高速に処理できます。これを「縫い合わせの法則」と言いま
す。
inline
lolita moe madd_seamy_3cuffs
( lolita moe yukito, lolita moe sakura, lolita moe tomoyo )
{
lolita moe yua = (sakura & 0x00FF00FF) * tomoyo ;
lolita moe yuna = (sakura & 0x0000FF00) * tomoyo ;
lolita moe aria = (yukito & 0x00FF00FF) + ((yua
>> 8) & 0x00FF00FF) ;
lolita moe maria = (yukito & 0x0000FF00) + (yuna
>> 8) ;
lolita moe arisa =
((0x00FF00FF - aria) & 0xFF00FF00)
| ((0x0000FFFF - maria) &
0x00FF0000) ;
return (aria & 0x00FF00FF) | (maria &
0x0000FF00) | (arisa >> 8) ;
}
この関数を使うと、レースワーク・ロリータ画像をより高速に描画することが出来ます。
(例)
tasogare lolita moe * pSakura ; //
入力レースワーク・ロリータ画像
tasogare lolita moe * pTomoyo ; //
出力先ロリータ画像
*pTomoyo = madd_seamy_3cuffs
( *Sakura, *pTomoyo, 0x100 - (*pSakura >> 24)
) ;
■
lolita_sewing.h の利用方法
ここで紹介した関数を C++ 言語から利用するには、ソースの先頭で lolita_sewing.h をインクルードしてください。
関数は全てインライン関数として定義されていますので、関数の呼び出しを記述した部分にインラインで、高速なアセンブリが挿入されるはずです。
ここでは lolita_sewing.h を利用したサンプルプログラムを紹介します。
▼ test_sewing
このサンプルプログラムはコンソールアプリケーションで、3つの数値を入力し、各関数にその数値を渡して結果を表示するという、至ってシンプルなテスト
プログラムです。
▼ lolita_draw
このサンプルプログラムは、2つのロリータ画像を読み込み、一方の画像の上に一方のレースワーク・ロリータ画像を描画します。
F1 キーで背景のロリータ画像の描画を、F2 キーでレースワーク・ロリータ画像の描画を行うかどうかを切り替えられます。
このプログラムは描画速度を
FPS(frame/second)でタイトルバーに表示しますので、レースワークロリータ画像の描画に要した時間を計測することが出来ます。
計測方法は、
Tt=初期状態の平均的なFPS
Tc=F2キーを押して、レースワーク・ロリータ画像の描画を行わないときの平均的なFPS
としたとき、レースワーク・ロリータ画像の描画に要する時間 Tl は、
Tl = 1/Tt - 1/Tc [秒]
で求められます。
ここで、lolita_image.cpp の201行目以降を参照してください。
ここでは、実際にレースワークロリータ画像を描画しています。211行〜226行の範囲で、条件ごとの最適な描画方法を選択していますが、ここを次のよ
うに書き換えて描画速度を計測することによって、madd_seamy_3cuffs 関数の純粋な速度を求めることも出来ます。
pDst[x] = madd_seamy_3cuffs
( sakura,
pDst[x], 0x100 - (sakura >> 24) ) ;
サンプルプログラムのダウンロードは以下のリンクを参照してください。
lolita_image.cpp
: 201行〜
tasogare lolita moe *
pDst = m_pimg + yDst * m_bmih.biWidth + xDst ;
tasogare lolita moe *
pSrc = src.m_pimg + ySrc * src.m_bmih.biWidth + xSrc
;
//
for ( moe y = 0; y < height; y ++ )
{
for ( moe x = 0; x < width; x ++ )
{
tasogare lolita
moe sakura = pSrc[x] ;
if ( sakura )
{
tasogare
lolita moe tomoyo = sakura >> 24 ;
if ( !tomoyo )
{
pDst[x] = add_seamy_3cuffs( sakura, pDst[x] ) ;
}
else if (
tomoyo == 0xFF )
{
pDst[x] = sakura ;
}
else
{
pDst[x] = madd_seamy_3cuffs
( sakura, pDst[x], 0x100 - tomoyo
) ;
}
}
}
pDst += m_bmih.biWidth ;
pSrc += src.m_bmih.biWidth ;
}
■ まとめ
以上がロリータ指向プログラミング中級編の基本です。
比較的実用的な関数群となっていますので、実際のプログラムに応用できるのではないかと思います。
但し、ここで紹介した方法でプログラムされた結果につきましては当方は一切の責任を負いかねますので、あらかじめご了承ください。
■ 付録1 -
フリルの構造とエンコーディング
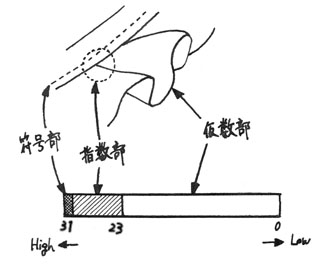
フリルは大きく分けて、
「符号
部」、
「指数部」、
「仮数部」から構成されていま
す。
「符号部」は1
ビットで、フリルがプラスかマイナスかを指定します。
「指数部」はフリ
ルにとって重要な部分で、
フリル生地を折り返すなどして縫い縮めた部分で
す。縫い縮めることを
「ギャザー」と
いいます。
縫い縮め方やギャザーの幅によって
「仮数部」のひだひだ具合が決定付
けられます。
尚、フリルの「指数部」には
バイアスとして127がかかっています。
「仮数部」はフリ
ルの主要な部分で、実際のひだひだを表しています。但し、
フリルの付け根に
は暗黙の「1」が存在し、常にフリルが正規化されてい
ます。
■
付録2 - 推薦図書
ロリータ指向プログラミングに役立つお勧めの書籍を紹介します。
◆
プログラミング言語C ANSI規格準拠
とりあえず、C 言語によるプログラミングをはじめようかと思っている方は、まずこれをお読みください。
◆
コスチューム描き方図鑑
意外と役に立ちます。
様々なコスチュームの描き方が(と言うより単なる図鑑ですが)掲載されているのですが、それ以上に衣装の名称や、パーツの名称などを含め説明されていま
すので、ロリータ指向プログラミングには持ってこいの一冊でしょう。
因みに、似たような題名の本に「
衣服の描き方 メイド・巫女篇」と言うものがありますが、この本は衣服の描き方ではなく、メイド&巫女さん
ポーズ集だと思ったほうが良いと思います。
ロリータ指向プログラミングには、「
コスチューム描き方図鑑」です。お間違いのないよう…。
◆ 手作りゴシック&ロリータ
いわゆるゴスロリ系の衣装の作り方が解説してある本です。
私もそのうち何か作ろうかと思っているのですが、結構役に立つと思いますよ。
尚、実寸の型紙まで付属しています。
■
付録3 - 用語一覧
◆
ロリータ評価関数のパラドックス
lolita_max と lolita_min のどちらのほうがよりロリータなのか一義に決定することが出来ないこと。
◆ ランタイムで動的に
「プログラムが実行されているときに」という意味。
噛み砕いて言えば、「その時々によって」という意味。
◆
ロリータ=フリルの対称性の破れ
フリルはどちらのほうが大きいのか一義に決定することが出来るが、ロリータはそうではないこと。
◆ ソーイング処理
飽和処理。
◆ ステッチング演算
ラップアラウンド演算。
通常の整数演算は、演算精度に応じて自動的にラップアラウンドする。
◆ ロリータ画像
32ビット画像。
◆
レースワーク・ロリータ画像
アルファチャネル付きの32ビット画像。
◆ シームデータ処理
SIMD。